
ChatGPT o1 Preview -- Does it Hold Promise for Lawyers?
A comparison of o1 and 4o performing legal tasks


I was excited about OpenAI’s release yesterday1 of OpenAI’s o1-preview. And so I spent hours today playing with it and comparing it to ChatGPT 4o. OpenAI is calling o1 a preview – not even an actual first version. The signal they are sending is clear—here is a taste, but it will get much better soon. I was curious how it would compare to 4o. OpenAI simultaneously released o1 mini, which is faster but has less advanced reasoning abilities, so I stuck with comparing o1-preview to 4o.
One of the practical problems with ChatGPT’s models 3.5, 4 and 4o, and other commonly used, general purpose models such as Claude and Gemini is that you have to break down more complex tasks into smaller tasks, or they return incomplete answers. These models also forget the beginning of the chat if the chat is too complex, and so it is necessary to make sure the tool stays on task by correcting it, or breaking the task into sub-parts. OpenAI was attempting to resolved these issues in o1. Instead of instantly shooting out a predictive answer like 4o, it flashes “Thinking” “Piecing together information” “Gathering details” “Clarifying guidelines” and other similar message
s2 while it goes through a multi-phase process with a step-by-step methodology to answer questions.
What OpenAI Says About o1-preview
Here are the things OpenAI boasts about o1:
Chain of Thought Reasoning: A key feature of o1 is its ability to engage in a chain of thought before responding. Instead of generating immediate answers, o1 “thinks” through problems in a series of steps, mimicking how a human might approach difficult questions. This method enables the model to break down complex problems into smaller, manageable parts and refine its thought process to produce more accurate and reasoned outputs.
Reinforcement Learning: o1 uses a large-scale reinforcement learning algorithm that trains the model to think productively and effectively. This training allows the model to learn from its past mistakes and improve its problem-solving strategies over time. As o1 receives feedback, it fine-tunes its approach, which enhances its ability to reason across diverse tasks.
Data Efficiency: The training process of o1 is described as highly data-efficient, meaning it can achieve high levels of performance without requiring excessive amounts of data compared to traditional models. This efficiency allows the model to generalize better across different domains and improve with less computational overhead. That’s great news for legal professionals who often are dealing with large amounts of information and documents. This will allow things like things like discovery review to be performed much more cost-effectively.
Train-Time and Test-Time Compute: o1’s performance scales with both train-time compute (the amount of compute power used during training) and test-time compute (the time it spends thinking before responding to a query). The model's reasoning ability improves with more computational resources, which suggests that its accuracy and depth of reasoning are linked to the amount of thought it invests in a given task.
Benchmark Performance: o1’s superiority is backed by empirical evidence from a variety of competitive evaluations solving mathematical and physics problems, among other things.
Consensus and Majority Voting: The model’s ability to re-rank answers using a learned scoring function, combined with a consensus-based approach (evaluating multiple samples), enables it to deliver even higher accuracy on challenging tasks by considering different possibilities and selecting the most likely correct answer.
The Good, the Bad, and the Ugly
I have reviewed a number of opinions on how good or bad o1 is, especially compared to 4o. I am still reserving judgment on how valuable and useful o1 is in legal tasks, but here are some things I like and don’t like about it, and my thoughts on how it will function for lawyers and in legal practice.
Legal Tasks
1. Legal Reasoning.3 My interest was piqued by the infographic that showed o1 was almost 10% better at “Professional Law.”

Image from OpenAI.com
Excited by that statistic, all the hype material by OpenAI, and some of the reviews I had read, I was eager to get started. I gave o1 this prompt:

Ok, too difficult. I was hopeful that with the advanced reasoning capabilities, I would not need to expend as much time and care on prompting. I was at least partially wrong. Either because o1 is just a preview, or because the model still needs specially-created prompts, I had to make my prompt more explicit. So I re-worked my prompt:

This answer was better, but 1L-ish. It was missing that promised reasoning capability. So I made a third attempt:

And here is the answer that took, as you can see, 8 seconds of wait time. I did not include the entire response o1 provided. Although o1 is not proficient at formatting, the answers are solid.

Upon receiving this answer I immediately switched to 4o and gave it the exact same prompt. Here is its response:

I compared the answers side-by-side. They were very similar. In this case 4o had the same depth of legal responses as o1 did, if not a bit more.
2. Legal Writing: I was curious about how well o1 could handle legal writing. It seemed as though the chain of thought and auto-correction capabilities would make it ideal for drafting. I gave this prompt to both 4o and o1:

Upon receiving the prompt, 4o quickly spit out a simple real estate purchase contract. It was very basic; something that a layperson would likely be able to draft without assistance. I asked it the following:

4o gave me 11 additional clauses that it said would make my contract better. They were all important clauses so I asked 4o to revise the purchase agreement, which it quickly did.
Upon giving the prompt to o1, it refused to do any legal drafting for me.

I really wanted to see its drafting capabilities, so I gave it this prompt:

I coaxed all of the paragraphs out of o1 paragraph by paragraph. I then gave it this prompt:

In return for my requested additional clauses and provisions, o1 gave me 20 excellent additional clauses, and 2 mediocre clauses that I could add to my contract to make it more high-level. I asked it to put all of the clauses together into one document. I thought it would refuse because it would not draft the document originally. It surprised me by agreeing.

The agreement it produced was not terrible. Of course, it included this proviso at the end, even though I told it I was a lawyer:

All in all, o1-preview’s real estate purchase agreement was far more robust than 4o’s agreement. They were both too basic to be anything other than drafts, but o1’s was far more advanced, even providing 2 exhibits that were disclosures. I was fairly impressed by o1’s performance on this simple drafting task.
3. Legal Reasoning: The true power of o1 is its reasoning capability. The reasoning capability is designed to address “complex problems in science, coding, math, and similar fields.” To test this reasoning ability in a legal context I gathered several cases on the topic of “theft of trade secrets” and gave each model this prompt:

I have used 4o many times for similar purposes, and was not surprised when it quickly returned a chart with the relevant principles from these cases. Wanting to test this on o1, I attempted to switch the user interface to o1, but ChatGPT responded that o1 cannot accept attachments. This was disappointing, but understandable since o1 is just a preview. Still looking forward to being awed by its reasoning abilities, I took the time to copy and paste each case into the o1 prompting field.

Here is what I received, in a well-formatted table:

But it then went on to give me two items I had not asked for, and not expected: a list of comparative observations. Here is the bottom section of the list:

The other item it provided me was a Conclusion section, somewhat akin to an executive summary.

There are many use cases where this type of summary would be helpful, especially as o1 evolves in its abilities.
Additional Benefits
1. Accuracy: If you’ve used any version of ChatGPT, or Claude or Gemini, or Grok or another tool, you know that like all LLMs it is subject to hallucinations. You occasionally must readjust your prompt by asking questions such as: “Are you certain? Please try that again.” Or “Walk me through why you said that.” What makes this version different, however, is its step-by-step methodology, called by OpenAI its chain of thought process. It will double check its own work. It can also view each word together, unlike 4o which often sub-word tokenizes (breaks apart individual words into smaller “tokens”). A great example of the difference this makes can be shown in this simple demonstration. I asked 4o:

It is disappointing that advanced technology such as this can’t correctly count the number of R’s in a single word. I understand that 4o uses sub-word tokenization (it breaks words into smaller parts), and that it analyzes each token, not each character. So it might have separated “strawberry” into “straw” and “berry” and only counted the R’s in “berry.” I also understand that it works on patterns rather than explicit algorithms for counting. Still, it lacks the capacity to perform a task that most 6-year-olds could successfully complete. Yet o1 handles the problem easily. I switched to o1 and asked the same question.
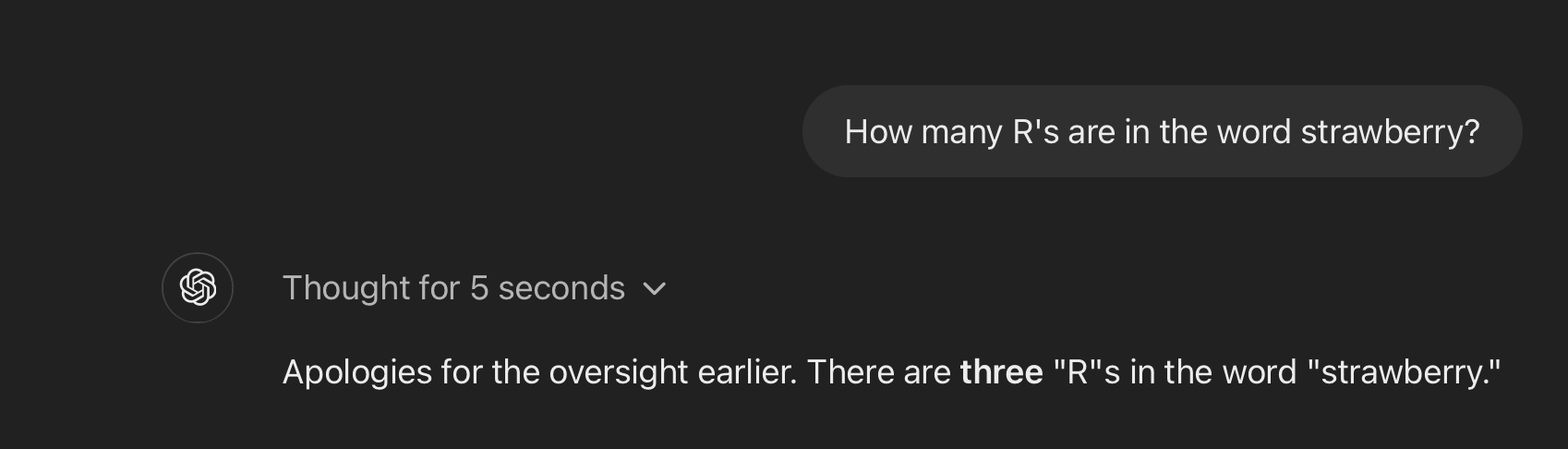
It not only got the answer correct, but it also apologized for 4o’s inaccuracy. Granted it took a surprisingly long 5 seconds to answer that simple question, but accuracy is worth the wait. I say ‘surprisingly long’ because it only took o1 8 seconds to analyze a lengthy motion to dismiss, and then provide a table with all the arguments and counterarguments. This accuracy with o1, however, gives me an added level of confidence that o1’s step-by-step approach has value.
2. Correcting Previous Mistakes: I like that o1 takes the time—we’re talking seconds here—to go through the step-by-step process of evaluating an issue and then responding. An analogy of the difference this makes is helpful. Imagine you’re doing a puzzle. Instead of trying to see the entire picture immediately, you first find the corner pieces, then the edges, and finally fit in the middle parts. Each step builds on the previous one, helping you gradually solve the puzzle. Similarly, o1’s chain of thought process works step-by-step, building up to the final solution. Rather than throwing out the most probable answer as quickly as possible, as other LLMs do, it methodically works out the answer step by step.
3. Adaptation: OpenAI o1-preview is trained to adapt and correct its strategies. This will happen over time, but it can even do this within a single chat to some extent. Because o1 uses the chain of thought technique, as mentioned above, it is able to refine its reasoning and problem-solving approaches during use. Specifically, by virtue of its chain of thought process o1 can reason through a series of steps, and if it encounters a complex problem, it may revise its approach. For example, if an initial reasoning path doesn't seem to be working, the model can attempt a different one within the same interaction, making adjustments in real-time as it processes the problem. And it’s doing all of this in mere seconds. Impressive.
It also has the benefit of being trained through Reinforcement Learning. Reinforcement Learning helps an AI model understand correct answers by receiving points. Imagine you’re playing a video game where you have to guide a character through a maze to find a treasure. Every time you make a move, the game gives you points when you’re heading in the right direction, but takes points away if you make a wrong turn. Over time, you learn from the game's feedback. If you get more points by going left, you’ll remember to go left next time. If you lose points by going right, you’ll try to avoid that in the future. Each time you play, you get better at finding the treasure because you're learning which moves help you win.
Reinforcement learning works in a similar way for computers and robots. They "learn" by getting feedback from their actions—like the points in the game. If the computer makes a good or desired choice, it gets a reward (like points), and if it makes a bad or undesired choice, it gets a negative score (like losing points). Over time, it figures out the best way to solve a problem or achieve a goal, just like you would in the game.
Conclusion
While I like a great deal about o1, what I like the most is its potential. This preview makes me even more excited about its first full version. Where o1 really shone was the task I gave both versions that emphasized legal reasoning. The insights and executive summary that o1 provided would be valuable in many use cases.
Version o1 is not even a full “version”; rather, it’s just a preview. But it is enough of a preview that I was able to ascertain that its strength lies in its advanced reasoning techniques, efficient learning process, and its ability to self-correct and adapt its strategies. These elements combine to create a model that will excel in reasoning-heavy tasks. To be clear, I am not ready to abandon 4o in favor of o1, but I see how much it promise it holds. Especially for the complex, nuanced practice of law.
OpenAI o1-preview was released September 12, 2024. I started writing this article the following day.
At the risk of sounding like I am anthropomorphizing o1, I will drop the quotation marks, and just include the words that are typically considered uniquely human abilities—or at least abilities exclusive to living animals—such as thinking, learning, and reasoning. Yes, I know this tool—and every other GenAI tool—is not alive.
As always, be certain not to input any confidential, sensitive or personal identifiable information into OpenAI’s o1-preview, or any other Generative AI tool without verifying the security and confidentiality in the End User License Agreement (EULA) and/or Terms of Service.